CV 基础(一)
CV 基础
Classification & Regression
In classification, the goal is to assign input data to specific, predefined categories. The output in classification is typically a label or a class from a set of predefined options.
In regression, the goal is to establish a relationship between input variables and the output. The output in regression is a real-valued number that can vary within a range.
In both supervised learning approaches the goal is to find patterns or relationships in the input data so we can accurately predict the desired outcomes. The difference is that classification predicts categorical classes (like spam), while regression predicts continuous numerical values (like age, income, or temperature).
What does patch in CV mean?
可以通俗地理解为图像块,当需要处理的图像分辨率太大而资源受限 (比如显存、算力等) 时,可以将图像划分成一个个小块,这些小的图像块就是 patch。例如,压缩感知重建算法通常取 128× 或 256× 图像块。
基于上述另外补充一点:为何要划分 patch 而不使用 resize 缩小分辨率呢?
通常情况下,resize 没有太大问题。但在处理图像分割问题时[1],由于是 dense prediction,属于像素级的预测,因此会尽量要求精确。
而 resize 操作大多是对图像进行插值处理,本质上一种滤波,在像素级别上会造成损失 (对传统图像处理有了解的应该知道某些滤波效果会使图像变得模糊),即:某些位置上的像素值是通过多个位置加权计算出来的,从而限制了模型预测结果的上限。因为你给的源图像本来就是不精确的,基于这不精确的源信号作为监督,训练出来的模型性能自然就局限在那里了。
相对地,划分 patch 只是把原来的大图分成一个个小图,而这些小图依然是原图的部分,像素值没有改动,因而在理论上,训练出来模型的上限能够比基于 resize 得到的图像训练来的高。
Backbone
在深度学习中,“Backbone” 通常指的是用于特征提取的主干网络或基础网络结构。它是模型的核心部分,负责从输入数据中提取有用的特征。Backbone 通常是一个预训练 CNN,例如 VGG、ResNet、Inception 或 EfficientNet (现在也许是 ViT,Swin,CLIP) 等。这些网络经过数据驱动的端到端训练,能够有效地捕捉图像或其他数据中的关键特征。
在许多任务中,例如目标检测、图像分割或图像分类,Backbone 会与其他网络组件结合使用,以实现更复杂的功能。例如,在目标检测中,Backbone 提供特征图,这些特征图随后被其他网络层(如 RPN 或 ROI Pooling 层)处理,以完成检测任务。
总之,Backbone 是深度学习模型中的一个重要组成部分,负责特征提取,并为后续的任务提供基础。
图像理解任务
- Classification
- Object Detection
- Semantic Segmentation
Unsupervised & Self-Supervised
While both methods learn from data without human-annotated labels, the primary difference lies in the way they use the data:
- Self-supervised learning makes use of the structure within the data to generate its own labels.
- Unsupervised learning seeks to uncover hidden patterns or structures within the data itself.
Self-supervised
1 | Input: "The quick brown fox jumps over the _____" |
In this case, the model is learning to predict the next word (“lazy”) based on the input (“The quick brown fox jumps over the”). It’s a self-supervised task because the label for training (the word “lazy”) is part of the data itself.
Unsupervised
For unsupervised learning, let’s consider an example with text clustering. Suppose we have multiple sentences, including multiple instances of our sentence, and we want to group similar sentences together:
1 | 1. "The quick brown fox jumps over the lazy" |
In this case, the model is learning to group similar sentences together without any explicit labels. Note that this is a highly simplified example, and real-world text clustering tasks would involve much more complex datasets and models.
表示学习
数据决定了机器学习的上限,而模型只是无限接近这个上限,所以数据的重要性不言而喻,然后数据就是所谓的特征工程——机器学习中必不可少的一个步骤,传统的特征工程非常依赖于人工经验,依赖于调参侠对于业务的理解而去选择认为有用的特征输送到模型中,不断的反复调整才可得出最优的效果。
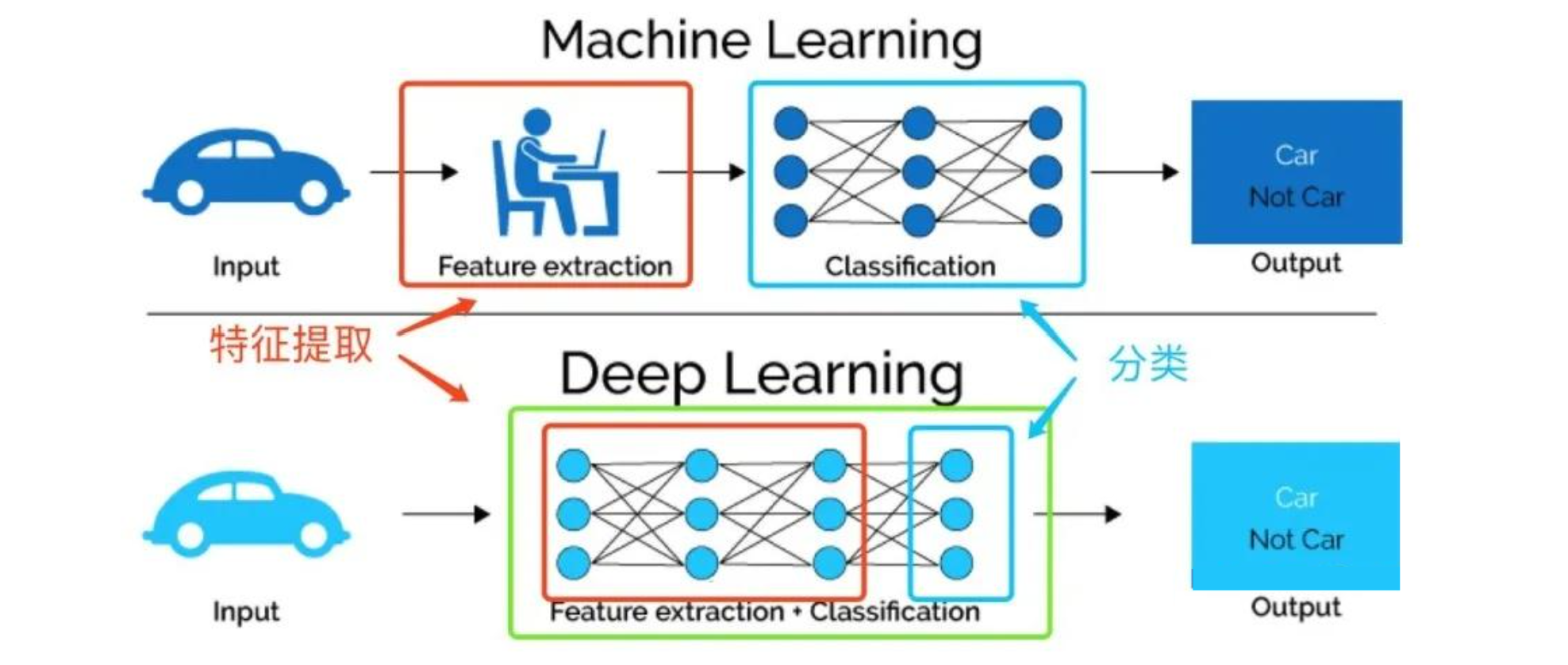
因此国内外才引入了表示学习。表示学习的基本思路,是不依赖于人工经验,自动的找到对于原始数据更好的表达,以方便后续任务。所以与传统的特征工程有一定的区别,如下图。
迁移学习
迁移学习(TL)是机器学习(ML)技术的一种,是指将针对一项任务预训练的模型进行微调以用于新的相关任务。训练新的机器学习模型是一个耗时且复杂的过程,需要大量的数据、计算能力和多次迭代才能投入生产。通过迁移学习,组织则可以使用新数据针对相关任务对现有模型进行重新训练。
Background & Foreground
background:在计算机视觉中,背景通常指图像中不引起关注的部分。这些部分通常作为环境或场景的一部分,为图像分析提供上下文信息。
foreground:前景是图像中感兴趣的对象或区域。这些通常是分析、检测或跟踪的主要目标。
Convolution
转置卷积 & 空洞卷积
转置卷积 通常情况下,对图像进行卷积运算时,经过多层的卷积运算后,输出图像的尺寸会变得很小,即图像被约减。需进行上采样 (Upsample),恢复图像尺寸,实现图像由小分辨率到大分辨率映射。基于先验经验的上采样插值,其效果不理想。希望让神经网络自己学习如何更好地进行插值,即转置卷积 (Transpose Convolution).
空洞卷积 在像素级预测问题中 (如语义分割),图像输入到网络中,经过卷积及池化计算,降低特征图尺寸的同时增大感受野。为使得输出图像的尺寸与原始的输入图像保持一致,使用转置卷积等进行上采样。由于下采样的信息丢失是不可逆的,上采样不可避免地遇到图像分辨率降低等问题。空洞卷积是针对此问题提出的卷积思路,其通过引入扩张率 (Dilation Rate) 这一参数使得同样尺寸的卷积核获得更大的感受野。相应地,也可以使得在相同感受野大小的前提下,空洞卷积比普通卷积的参数量更少。
空洞卷积在语义分割 (Semantic Segmentation) 等领域得到广泛应用。
Pixel Shuffle / Unshuffle
where:
- = original height, width, channels
- = upscaling factor
- = convolutional operations
PixelShuffle(Sub-Pixel Convolutional Neural Network,像素重组)是一种经典的上采样方法,可以对缩小后的特征图进行有效的放大操作。
PixelShuffle 现已广泛应用在如图像分割等计算机视觉问题上,和反卷积一起成为了神经网络中最常用的两种上采样技术。相比之下 PixelShuffle 克服了反卷积的易产生棋盘格的问题。
UpSampling
上采样 (Upsampling) 是深度学习中将低分辨率特征图 (或信号) 扩展到高分辨率的关键操作,常用于图像分割、超分辨率、生成对抗网络 (GAN) 等任务。
常见 UpSampling 手段对比。
| 方案 | 代码 | 描述 |
|---|---|---|
| 转置卷积 (Transposed Convolution) | nn.ConvTransposed2d |
棋盘效应 |
| 最近邻上采样 (Nearest Neighbor Upsampling) | nn.Upsample(mode='nearest') |
块状伪影 |
| 双线性插值 (Bilinear Interpolation) | nn.Upsample(mode='bilinear') |
模糊 |
| 子像素卷积 (Sub-Pixel Convolution) | nn.PixelShuffle(nn.Conv2d) |
\ |
MLP
通过在网络中加入一个或多个隐藏层来克服线性模型的限制, 使其能处理更普遍的函数关系类型,这就是 MLP 的思想。 最简单的方法是将 个全连接层堆叠在一起,把前 层看作表示,最后一层看作线性预测器。这样的架构实际上并没有增强模型的表示能力,因为仿射函数的仿射函数本身就是仿射函数, 而单一线性层已经能够表示任何仿射函数。
为此,在仿射变换之后对每个隐藏单元应用 激活函数
一般来说,有了激活函数,就不可能再将 MLP 退化成线性模型。进一步地,可以继续堆叠隐藏层,例如 和 ,从而产生更有表达能力的模型。
Image Inpainting ↩︎




